SQL Express database size
This article is an updated of my previous January 2014 article
SQL Server 2012 Express edition is a great database with a lot of potential. There are some limitations, but for a lot of applications this isn’t a big deal and SQL Server express is a great choice.
For SQL Server 2012 Express edition, the following limitations exist:
- Each engine will use only up to 1GB of RAM memory.
- Each engine will use only 1CPU (with a maximum of 4 cores within that CPU).
- Each database can grow up to 10GB in size.
If you exceed the possibilities of SQL Server Express editions, then you need to upgrade to at least the Web edition or the Standard edition (depends on your use-case). Both licences cost serious money, so the Express edition might be a good candidate.
Always make sure that you know the consequences if your use-case doesn’t fit Express anymore. You might want to start with a free database (i.e. MySQL) instead.
Don’t combine databases
The limitations are per SQL Server engine or per database. Each database belongs to a single engine. Don’t combine data for multiple purposes into a single database. This is already a bad idea from a point of maintenance, but you might also reach one of the limitations earlier. Unrelated data should always be stored in separate databases.
Keep large BLOBs out of your database
It seems tempting to store large binary objects inside your database. The advantage is that you keep all data together, but at the expense of database size (which is precious in Express). It’s often a better idea to store large BLOBs outside the primary database using FILESTREAMs.
Another option is to store the files on disk and only keep the filename in the database. This requires additional handling in the business logic, because you need to delete the files on disk, when the associated record in the database is removed. You also need to change the logic to obtain the actual files. This might be an advantage, because files have much better support in C# then database BLOBs. It’s quite easy to return a stream to file, but streaming from a database BLOB is much harder.
If you do want to keep your BLOBs in the database, then consider to use a separate database for your BLOBs. It’s fine to keep this database in the same engine, if you don’t expect to use the BLOBs a lot.
Trending data often requires a lot of storage and is often less relational. Consider to offload this kind of data to another database that is better suited for this kind of data. Consider using a NoSQL database like MongoDB or Influx instead.
Choose your indexes wisely
First of all, you need to choose your indexes wisely no matter what kind of SQL Server you use! The size of your indexes is added to the total database size, so you may reach the 10GB size limit, because you have defined large indexes. SQL Server always creates indexes for your primary keys. A lot of people think that adding a foreign key also creates an index, but this isn’t true. Although it is often a good idea to have an index on your foreign keys, it’s not done by SQL Server implicitly (for very good reasons).
SQL Server indexes are too complex to handle in this post, but I will try to give you some guidelines. There are actually two different kind of indexes, the clustered index and the non-clustered index.
There can only be one clustered index per table. All records in a table are stored in some sort of tree structure. If you add a clustered index, then the records in this tree are populated in the order of the indexed columns. From a logical perspective, you could state that the indexed columns determine the physical ordering of the records.
Besides the clustered index, you can also create nonclustered indexes (it’s actually the default for an index). Look at a nonclustered index as a hidden table that contains the indexed columns and an additional column that points to the actual logical record in the table. Accessing columns that are not in the clustered index requires an additional indirection to the original table, so nonclustered keys can be considered slower then the clustered index. If you access only one column often, then you can include this column in the index as well. The additional column will also occupy space, so your index becomes larger.
If you don’t have any clustered indexes, then your table will be stored with a heap typed index. This index results in a table scan, if no other indexes apply. It’s generally a bad idea to have heap indexes, unless the table contains only a few records. So always try to specify a clustered index (primary key or one of your other indexes). The heap index also uses data, so always use a clustered index. It will also make a transition to Azure SQL easier, because it requires a clustered index for each table.
Updating data (insert, update, delete) also affects the indexes if the column is included in the index. Don’t optimize your indexes only based on SELECT queries, but also take writing into account.
Choose your key types wisely
I often see that people use UUIDs, because they’re always unique and makes life easier (I was one of them). But key values are often referenced using foreign keys and indexes. If you choose a UUID instead of an integer, then keep in mind that the UUID takes 16 bytes and the integer only 4 bytes. Each time the key is referenced (primary key, foreign keys and indexes), it will take up 4x more space.
If you don’t think you will hit the limits of integers and you don’t plan to use replication in the future, then consider using integers instead of UUIDs. It will help to keep your database smaller and faster. Comparing integer values is much faster then comparing UUIDs.
Integers will have disadvantages if you distribute the database across multiple servers. UUID are globally unique, where integers are not. Using integers makes it much harder to distribute the data. Changing identifiers in a production database is hard and requires significant downtime and risks.
Know the size of your database
If you want to know if you’ll hit the database size in the near future, then you should keep track of your current database size. You can use the sp_spaceused stored procedure, but it only reports the amount of space that is allocated by your database and not the amount of storage that is actually in use.
The easiest method to determine the size of your database is to generate a standard report, from within SQL Server Management Studio. Select the database in the tree and right-click on it. Then select the Reports/Standard Reports/Disk Usage report. It will show you something like this:
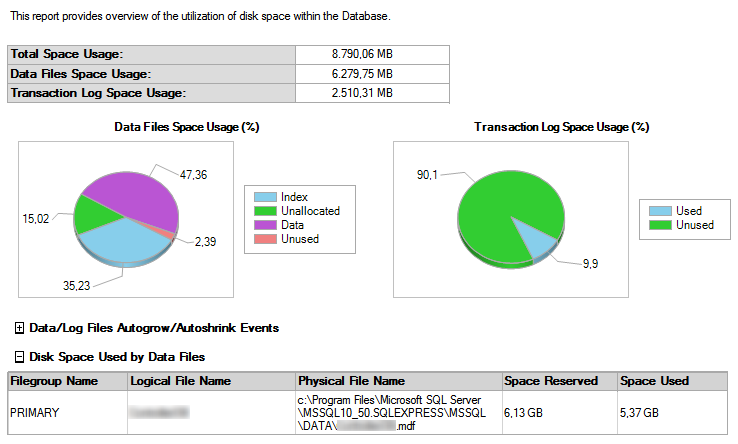
The total space usage is almost 8.8GB, so it seems that we would hit the 10GB barrier pretty soon. But this space includes the transaction log and it also includes all unused space within these files. The actual database size is 5.37GB. SQL Server Express will start complaining when it cannot reserve any more space for the datafile.
Did you also notice that indexes take up 35% of the total database size? The actual data uses 47%, so take your index seriously. There is also another report that shows you the amount of used data per table. It also shows the amount of data that the indexes, associated with each table, take up. Some tables uses more space for their indexes, then the data itself.
Monitor the amount of space using SQL queries
You probably don’t monitor the size of your database regularly, when it is in production. You can create a scheduled task that monitors the size of your database on a regular basis and send an email when the database grows too large.
SELECT
[name] AS [Filename],
[size]/128.0 AS [Filesize],
CAST(FILEPROPERTY([name],'SpaceUsed') AS int)/128.0 AS [UsedSpaceInMB],
[size]/128.0 - CAST(FILEPROPERTY([name],'SpaceUsed') AS int)/128.0 AS [AvailableSpaceInMB],
[physical_name] AS [Path]
FROM sys.database_files
This query will show you the size of the database files. You only need to monitor the used space of the datafile (.mdf). If you need more detailed information about the size of the tables/views and your indexes, then use the following query:
SELECT
o.name AS ObjectName,
o.type AS ObjectType,
i.name AS IndexName,
i.type_desc AS IndexType,
p.rows AS Rows,
SUM(a.used_pages) * 8 AS UsedSpaceKB
FROM (
SELECT 'table' as type, t.name, t.object_id FROM sys.tables t
UNION
SELECT 'view' as type, v.name, v.object_id FROM sys.views v
) o
INNER JOIN sys.indexes i ON o.object_id = i.object_id
INNER JOIN sys.partitions p ON i.object_id = p.object_id AND i.index_id = p.index_id
INNER JOIN sys.allocation_units a ON p.partition_id = a.container_id
GROUP BY o.name, o.type, i.name, i.type_desc, p.rows
ORDER BY o.name, i.name
It will show you the number of rows and the allocated space of each table/view and index.